| 豆瓣 top250 电影 python爬虫,数据分析,词云,饼图,柱状图 | 您所在的位置:网站首页 › 电影TOP50 豆瓣 › 豆瓣 top250 电影 python爬虫,数据分析,词云,饼图,柱状图 |
豆瓣 top250 电影 python爬虫,数据分析,词云,饼图,柱状图
|
最近突然对 python 的爬虫感兴趣,就花了两三天时间自己试了试。借鉴了一些他人的代码,自己也在网上查了查,实现了自己想要的分析。 分析结果用下面的图形表示:
具体代码如下: # -*- coding: utf-8 -*- """ Created on Sun May 5 14:08:23 2019 @author: zhen chen MIT Licence. Python version: 3.7 Email: [email protected] Description: This a practice for crawler in the movie reviewing website douban, crawling for top250 movies, and analyze their result """ import requests # 联系网络的包,a package for requesting from websites import xlwt # 读写 excel 的包,a package for reading and writing in excel, not supporting xlsx writing from bs4 import BeautifulSoup # 分析网页数据的包,a package for webstie data analysis from collections import Counter # 计算列表中元素的包,counter the num of each element in a list import collections import matplotlib.pyplot as plt # 画图的包 from pylab import mpl # 设置图形中字体样式与大小的包 mpl.rcParams['font.sans-serif'] = ['SimHei'] mpl.rcParams['font.size'] = 6.0 import time import random import jieba # 中文分词包 from wordcloud import WordCloud # 词云包 import re # 正则表达式包,for cutting the punctuations headers = { 'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.108 Safari/537.36', 'Host':'movie.douban.com' } ## data needed movie_list_english_name = [] movie_list_chinese_name = [] director_list = [] time_list = [] star_list = [] reviewNum_list = [] quote_list = [] nation_list = [] category_list = [] num = 0 for i in range(0, 10): link = 'https://movie.douban.com/top250?start=' + str(i*25) # 250部电影一共 10个网页, 10 pages for total 250 movies res = requests.get(link, headers = headers, timeout = 10) time.sleep(random.random()*3) # 每抓一个网页休息2~3秒,防止被反爬措施封锁 IP,avoid being blocked of the IP address # res.text is the content of the crawler soup = BeautifulSoup(res.text, "lxml") # lxml 是一个解码方式,lxml is one decoding model for Beautifulsoup div_title_list = soup.find_all('div', class_ = 'hd') # 寻找 hd 类型的类,find classes whose tag are hd div_info_list = soup.find_all('div', class_ = 'bd') div_star_list = soup.find_all('div', class_ = 'star') div_quote_list = soup.find_all('p', class_ = 'quote') for each in div_title_list: # a表示 html 中的超链接,a is href link of html # strip 去掉收尾的空格,strip() is for stripping spacing at the beginning and end of a string movie = each.a.span.text.strip() # 只能得到第一个字段,only get the first span of text this method movie_list_chinese_name.append(movie) # 通过css 定位得到第二个字段,从而得到英文名字,get second span by css location div_title_list2 = soup.select('div.hd > a > span:nth-of-type(2)') for each in div_title_list2: movie = each.text #movie = movie.replace(u'\xa0', u' ') movie = movie.strip('\xa0/\xa0') # 去掉英文名字中的空格,strip the extra string in the english name movie_list_english_name.append(movie) for each in div_info_list: num += 1 info = each.p.text.strip() if len(info) |
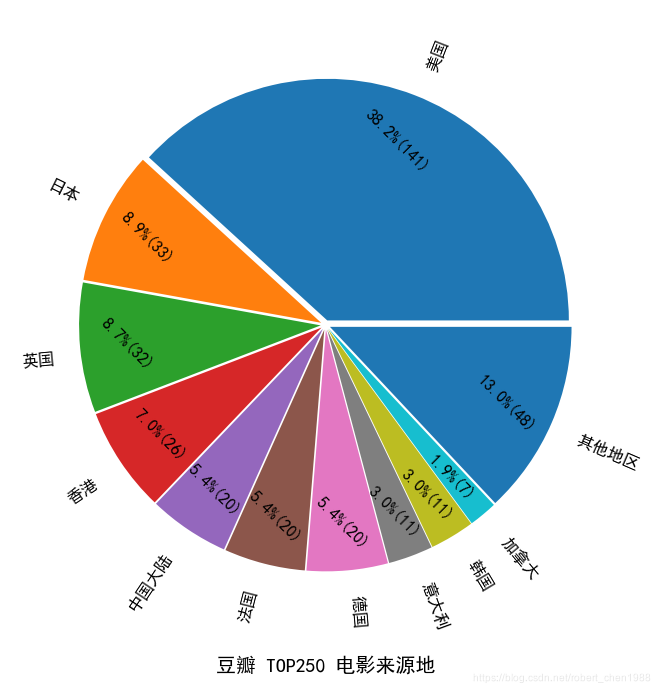
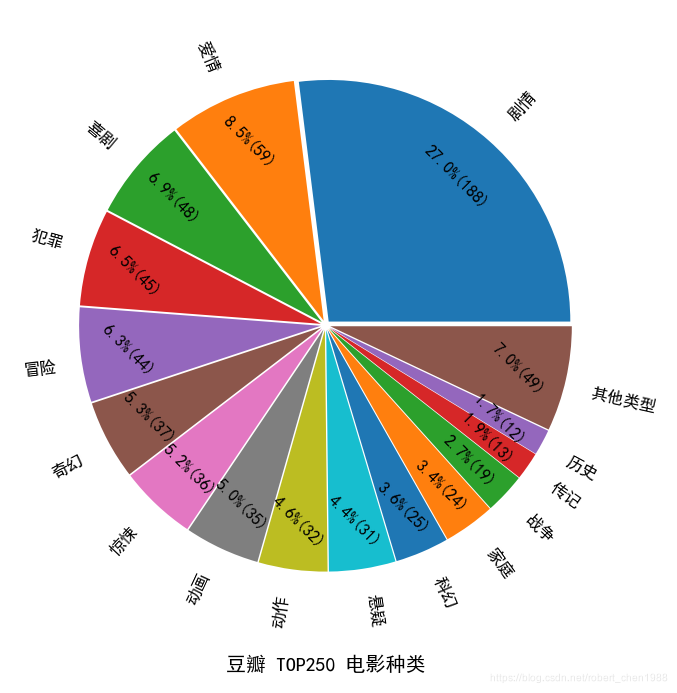

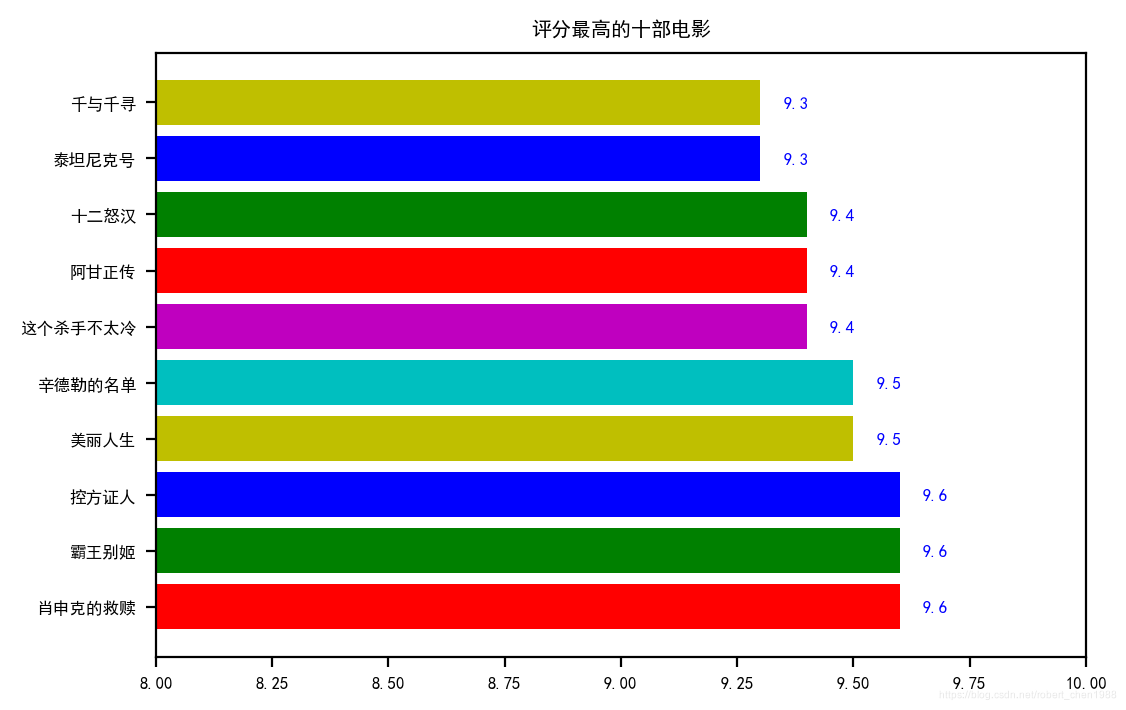
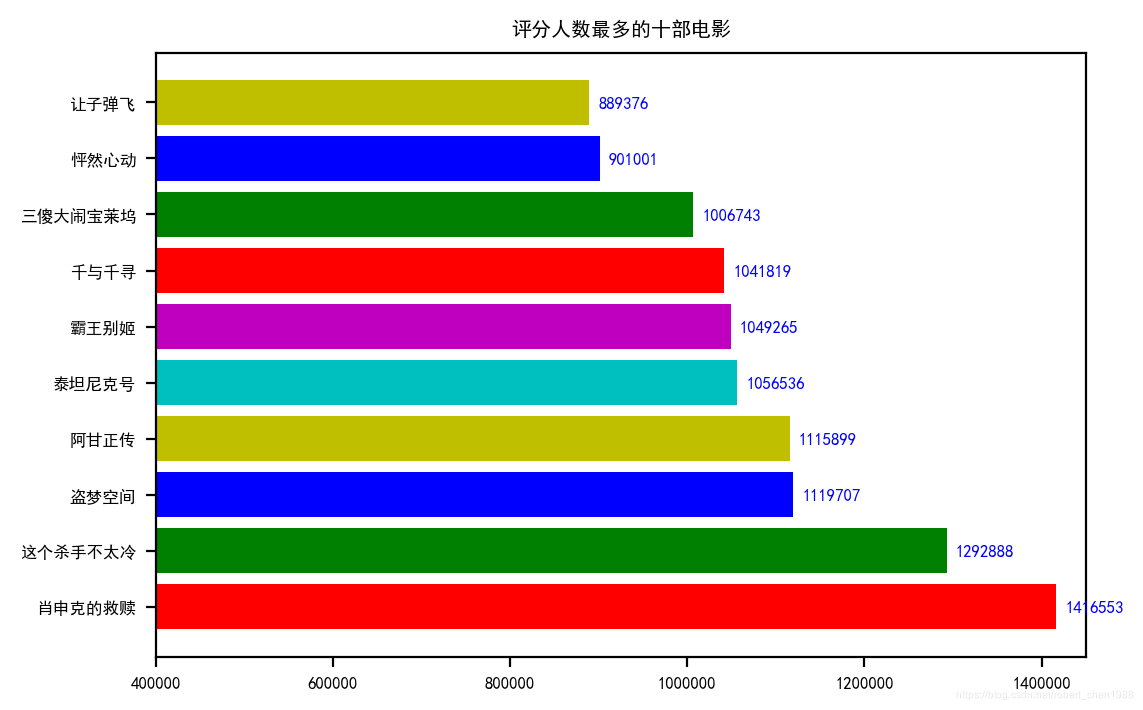
【本文地址】
公司简介
联系我们